
Note: This description is for those who are familiar with the basics of the Python programming language, able to install Python libraries and run Python code. For a quick start, see the official Python Tutorial.
Why choose Python?
The Python language is by far the most commonly used language for web scraping tasks, so most tools and libraries are available for this. In addition, it is a relatively easy and well-known programming language.
Version of Python and libraries used
The code before is tested with Python 3.6.9, so any Python 3 with a version 3.6 or higher should work. There are many frameworks and libraries to support scraping, but for this tutorial we’ll only use two of the simpler and smaller libraries:
- requests (version in this tutorial: 2.26.0)
- bs4 (version in this tutorial: 4.9.3)
Choice of website
In this example, we’ll download electronic products from the classified ads website jófogás.hu and export them to CSV. The direct link to the listings: https://www.jofogas.hu/magyarorszag/muszaki-cikkek-elektronika
For the sake of simplicity, we won’t implement pagination in this tutorial, and only scrape product data from the first page.
Planning
Our first task is to plan how we will extract the specified data. We will use Chrome’s Development Tools for this – but you can also use other browsers with minor modifications.
First, open the link above, then find an item in the list from which you want to collect data. Right-click on this item and select “Inspect” from the list. Then navigate in the pop-up window to find the item in the HTML that contains the entire product, not just the image, or the title if only part of it is currently selected. As we hover over the items, it always selects the relevant part of the webpage when we find the right item, so it will look something like this:
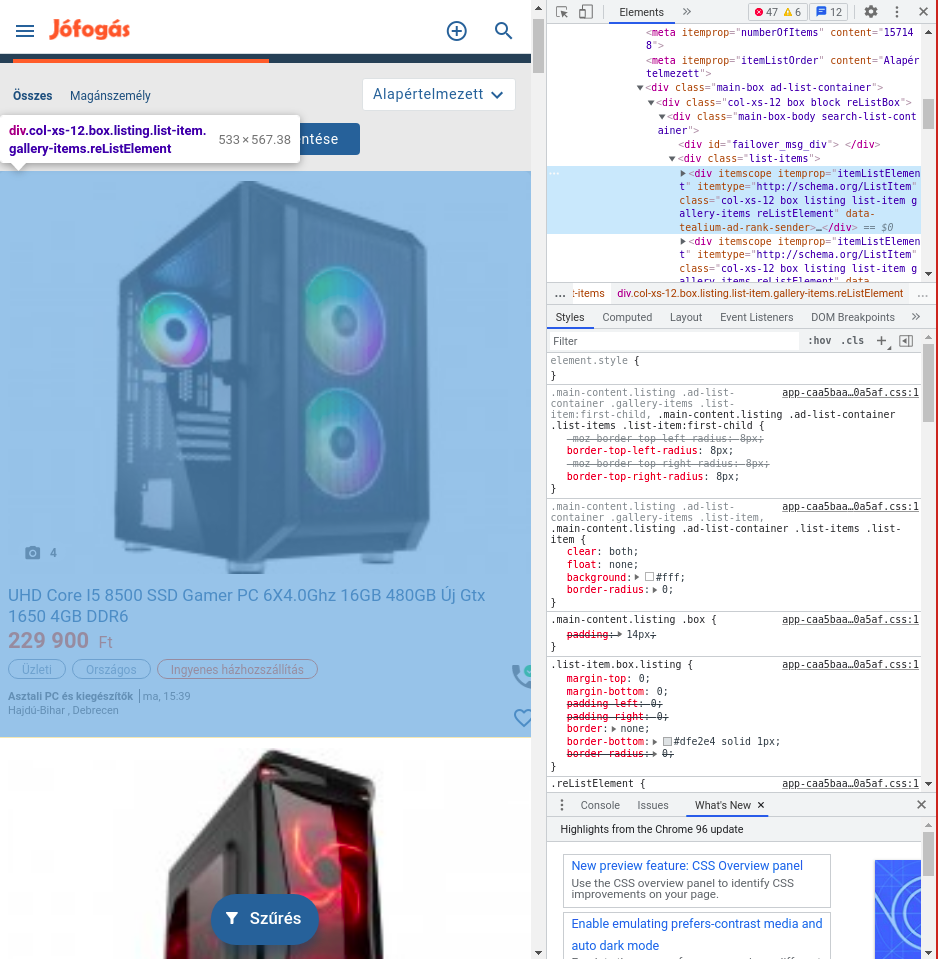
You can see that the entire product list item is in a “div” item. In general, these are well identifiable with the “class” property. There are several “classes” separated by spaces. It’s assumed that “list-item,” for example, will characterize list items well since that’s exactly what that means – but we can test later to see if that’s really enough. Based on the above, we can assume that the elements of the product list are “div” elements, which can be characterized by the “list-item” class.
By clicking on the left arrow next to the div element and expanding it, we can also find that the product name has an “item-title” class in the “h3” element and a “span” element in the forint element with a “price-value” class.
Based on this research, we can start coding.
The program
See explanations of what each part does in the comments:
# First we import the required libraries:
import csv
import requests
from bs4 import BeautifulSoup
# we store the URL we're scraping in a variable
url = "https://www.jofogas.hu/magyarorszag/muszaki-cikkek-elektronika"
# we download the page conent with the requests library
html = requests.get(url).content
# we parse the HTML content with the bs4 library
soup = BeautifulSoup(html)
# we find the products using the "list-item" class
termekek = soup.find_all('div', { "class": "list-item" })
# we define the result variable
results = []
# we loop through the products, and add each product's data
# as a dict object
for termek in termekek:
results.append({
"name": termek.find("h3", { "class": "item-title" }).text.strip(),
"price": termek.find("span", { "class": "price-value" }).text.strip(),
})
# finally, we write the results to a CSV file
with open('products.csv', 'w') as f:
fieldnames = ['name', 'price']
writer = csv.DictWriter(f, fieldnames=fieldnames)
writer.writeheader()
for result in results:
writer.writerow(result)Results
Save the code above to the file scraper.py and run it from the command line:
python3 scraper.pyAfter completion, we can see a file named “products.csv” in the same directory. The content will be similar to:
| name | price |
|---|---|
| Sony Playstation 5 / Ps5 (digital / lemezes) 2 év garanciával | 268 500 |
| UHD Core I5 8500 SSD Gamer PC 6X4.0Ghz 16GB 480GB Új Gtx 1650 4GB DDR6 | 229 900 |
| Core I7 SSD Pubg Gamer PC 8X3.6Ghz 16GB 500GB Gtx 1050TI 4GB DDR5 3D | 169 900 |
| Új Core I5 10400 SSD Gamer PC 6X4.3Ghz 16GB 1.0TB Gtx 1650 4GB DDR6 3D | 259 900 |
| Új RGB Asus 10GEN SSD Gamer PC! 4X4.0Ghz 16Gb 480GB Gtx 1650 4GB DDR6 | 239 900 |
| Új Gamer PC i5-10400F/RX 6600 8Gb (Rtx 3060 Szint)/16Gb/500Gb SSD/1Tb | 435 000 |
| Xbox 360 E slim Limitált! Kék 500GB dobozos Rgh! 83 játékkal! xbox360 | 44 990 |
| HP 8470P Core I5 Fortnite Gamer Start Laptop 8GB 500GB 1Év GAR! | 59 900 |
| Új 4K Dell Core I5 10400 SSD Gamer Erőmű PC: 16GB Gtx 1650 Super DDR6 | 249 990 |
The code and methods above works well for scraping list data on many websites, only changing the class names used.
Further considerations
Many websites load the data dynamically in the browser, using Javascript, so directly getting the HTML of the site may not work for certain websites. Apart from this, we didn’t make any effort here to hide our activity, so with high-scale web scraping, most services would automatically block our script.
If we run into either of these problems, a common solution is to use browser emulation. Most commonly in Python, we use the library Selenium.

0 Comments